

Pengertian dan Fungsi Robots.txt Pada Website
The Robots Exclusion Protocol (REP) atau Robots.txt adalah sebuah file yang berisikan peraturan crawling untuk Search Engine. Umumnya fungsi robots.txt digunakan untuk memblokir halaman yang tidak ingin di index atau diikuti oleh Search Engine. Entah itu mengizinkan Google dan sebangsanya untuk crawling website, ataupun tidak.
Terletak di root folder website kalian. Bersamaan dengan .htaccess dan subfolder lain. Beberapa tahun terakhir Robots.txt sangatlah populer bagi pengguna website baik wordpress, blogger, joomla dan lainnya. Karena fitur ini memberikan kemudahan pada developer untuk mengatur privasi website mereka.
Mau tau pengertian dan fungsi robots.txt pada website?
Search Engine Apa Yang Support Robots.txt?
Coba kita lihat tabel dibawah!
| Robots value | Yahoo! | MSN / Live / Bing | Ask | |
|---|---|---|---|---|
| index | Yes | Yes | Yes | Yes |
| noindex | Yes | Yes | Yes | Yes |
| none | Yes | Doubt | Doubt | Yes |
| follow | Yes | Doubt | Doubt | Yes |
| nofollow | Yes | Yes | Yes | Yes |
| noarchive | Yes | Yes | Yes | Yes |
| nosnippet | Yes | No | No | No |
| noodp | Yes | Yes | Yes | No |
| noydir | No use | Yes | No use | No use |
Fungsi Perintah Robots.txt
- index : Membiarkan halaman yang dimaksud untuk dilihat dan diindex pada pencarian
- noindex : Tidak mengizinkan mesin pencari mengindeks halaman yang dimaksud
- noimageindex : Tidak mengizinkan gambar untuk di index mesin pencari. Ini digunakan oleh instagram
- follow : Pada defaultnya semua halaman memiliki perintah follow. Agar tiap halaman diikuti oleh robot pencarian
- nofollow : Kebalikan dari follow. Memblokir akses robot pencarian terhadap link
- noarchive : Tidak mengizinkan mesin pencari memberikan data cadangan halaman yang dimaksud
- nocache : Sama seperti noarchive hanya saja khusus dibagian cache
- nosnippet : Tidak mengizinkan mesin pencari memunculkan kalimat potongan dari Halaman yang dimaksud
- noodp : Tidak mengizinkan mesin pencari menggunakan deskripsi halaman dari DMOZ
- noydir : Perintah khusus Yahoo! directory
- none : ini perintah yang paling mantap. Artinya Robot pencarian dilarang melakukan apapun
- Disallow : Perintah untuk tidak mengizinkan search engine
Contoh Robots.txt File Yang Benar
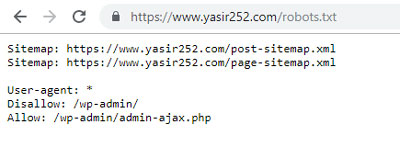
Untuk melihat file Robots.txt di website, kalian cukup akses URL website dan diikuti dengan /robots.txt. Contoh : Yoast Robots atau NeilPatel Robots Kurang lebih, tampilan default dari robots.txt file adalah seperti ini :
User-agent: * Disallow: /ebooks/*.pdf User-agent: Googlebot-Image Disallow: /images/
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Dari kedua kode diatas, mereka memiliki fitur yang berbeda. Khusus untuk kode paragraf kedua, itu adalah robots txt default yang di generate oleh WordPress. Untuk selengkapnya lihat penjelasan dibawah.
- User-agent: * — Mendeklarasikan semua jenis Search Engine Robot (*)
- Disallow: /ebooks/*.pdf — Melarang semua jenis robot, untk mengakses semua url (*) ebooks dan file PDF
- User-agent: Googlebot-Image — Mendeklarasikan Googlebot image untuk tidak mengakses gambar
- Disallow: /images/ — Disallow Google Bot Image mengakses url /images/
- Disallow: /wp-admin/ — Disallow Google Bot Image mengakses url /wp-admin/
Perlukah Menulis Sitemap di Robots.txt?
Memang secara teori menulis Sitemap di Robots.txt adalah benar. Tapi saya rasa hal itu tidak terlalu berguna untuk sekarang. Pasalnya, kita tetap wajib untuk membuat akun di Google Search Console atau Bing Webmaster Tools.
Barulah dari panel tersebut, kita bisa submit Sitemap website secara menyeluruh. Baca disini untuk cara submit sitemap ke Google, Bing, dan Yandex.
Ini alasan kenapa banyak website tidak menginput sitemap di file robots. Semoga bermanfaat!